是根据当前油藏状态制定各产油井和注水井的最优开发方案,从而获得最高的经济效益。然而,优化过程依赖计算耗时的数值模拟,且井间、层间相互干扰严重,非线性较强,求解难度大。因此,开发更有效的优化方法是研究的重要攻关方向。
而限制现有方法性能的一个主要原因是目前方法优化得到的解仅适用于特定的场景。然而,地下油藏模型具有强不确定性,同时在模拟器中优化得到的方案在实际部署时会受到受到限制,致使得到的方案在现场应用时变为次优解。因此,研究调控策略的鲁棒性和泛化性对于实际油藏开发来说尤为重要。
突破创新:为解决上述问题,张凯教授团队使用深度强化学习算法训练注采优化控制策略,并结合无监督域自适应技术解决策略泛化能力差的问题。该研究解决了现有方法优化的解仅适用于特定场景的问题,可从不同模型间学习共享的特征状态空间,并基于此状态空间训练控制策略,从而使其能够泛化到新场景。该工作以《Deep reinforcement learning and adaptive policy transfer for generalizable well control optimization》发表于《Journal of Petroleum Science and Engineering》。
文章内容简介:针对井控优化中的泛化问题,提出了一种基于深度学习的自适应鲁棒表示决策迁移(DLRDT)框架。具体来说,DLRDT使用三个阶段的工作流程来训练人工智能体。首先,智能体利用域自适应技术学习隐状态表示,理解当前油藏状态。其次,智能体利用高性能的深度强化学习算法在隐状态空间中训练最优控制策略。最后,将智能体迁移到训练过程中未见到的环境中进行评估。基于两个三维油藏模型的实验结果表明,本文所提出的算法具有良好的优化效率和泛化性能。
论文信息:
该工作以《Deep reinforcement learning and adaptive policy transfer for generalizable well control optimization》发表于《Journal of Petroleum Science and Engineering》上。论文通讯作者为中国石油大学(华东)张凯教授,第一作者为中国石油大学(华东)王中正。该工作得到了国家自然科学基金的资助、山东省自然科学基金项目、中国石油集团公司重大科技项目、国家科技重大专项的资助。
引用:Wang Z, Zhang K, Zhang J, et al. Deep reinforcement learning and adaptive policy transfer for generalizable well control optimization [J]. Journal of Petroleum Science and Engineering, 2022, 217, 110868.
文章链接:https://doi.org/10.1016/j.petrol.2022.110868.
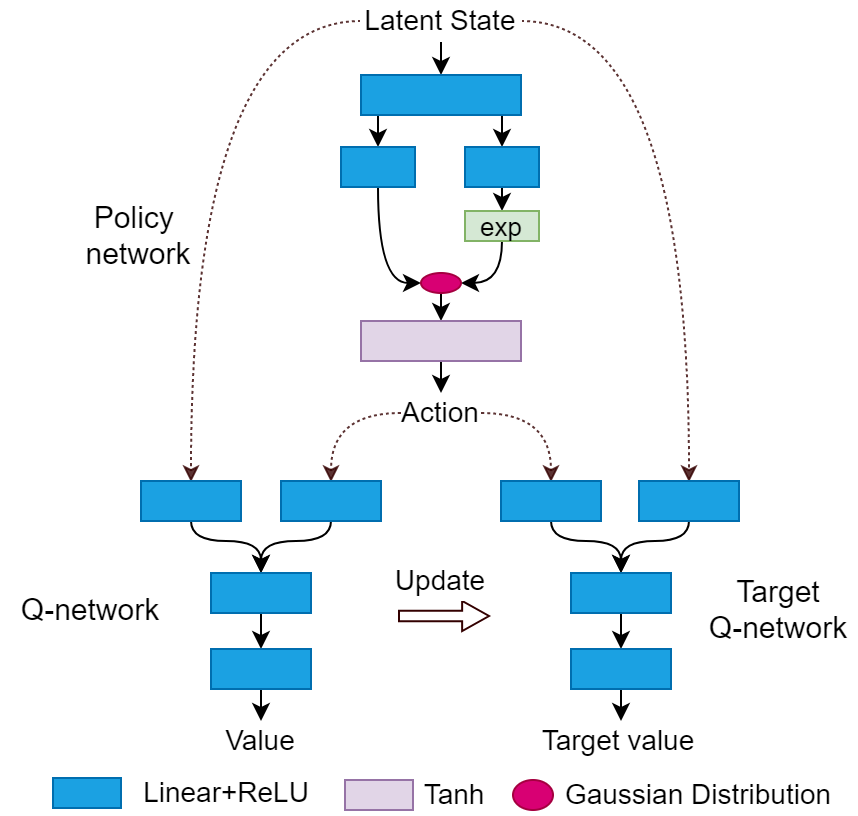
图1强化学习决策模型示意图
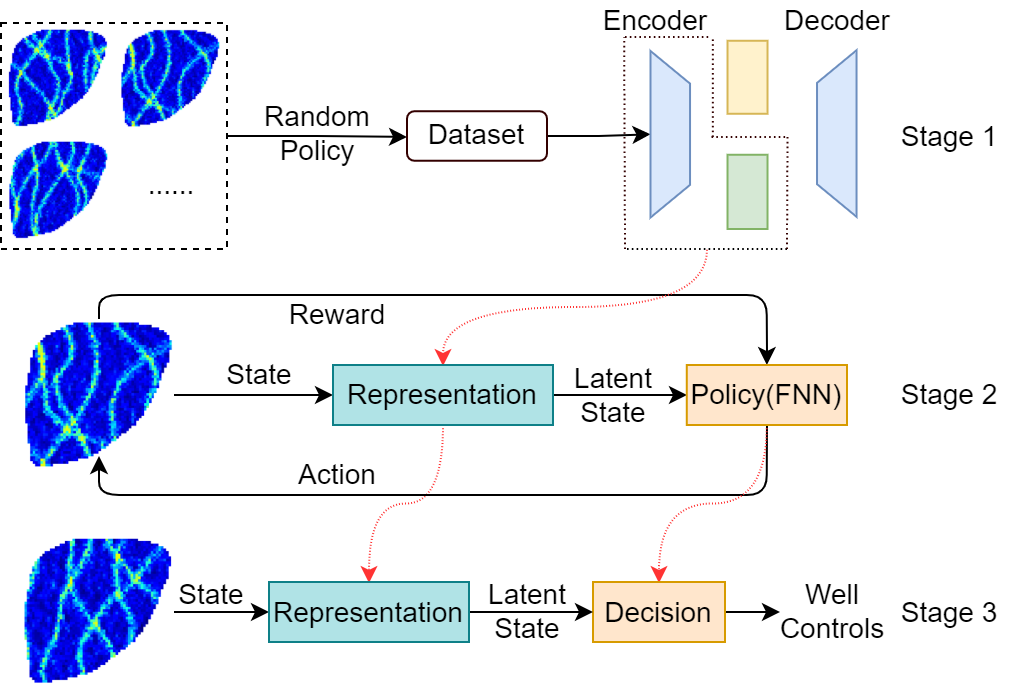
基于深度学习的自适应鲁棒表示-决策-迁移(DLRDT)框架示意图
